CQL Scoring & Disqualification Rules
Score for fit + intent and disqualify fast to protect focus.
Primary CTA: “Copy the Scoring Model”
Modern pipelines drown in “maybe.” The fastest path to revenue is separating who could buy from who will—and getting unqualified contacts out of the way without burning the relationship. This article gives you a practical, defensible CQL (Conversation-Qualified Lead) scoring model that blends fit (ICP match) and intent (buying readiness), paired with crisp disqualification (DQ) rules and an operating rhythm that keeps your model honest over time.
H2 Fit vs intent: signals and weights
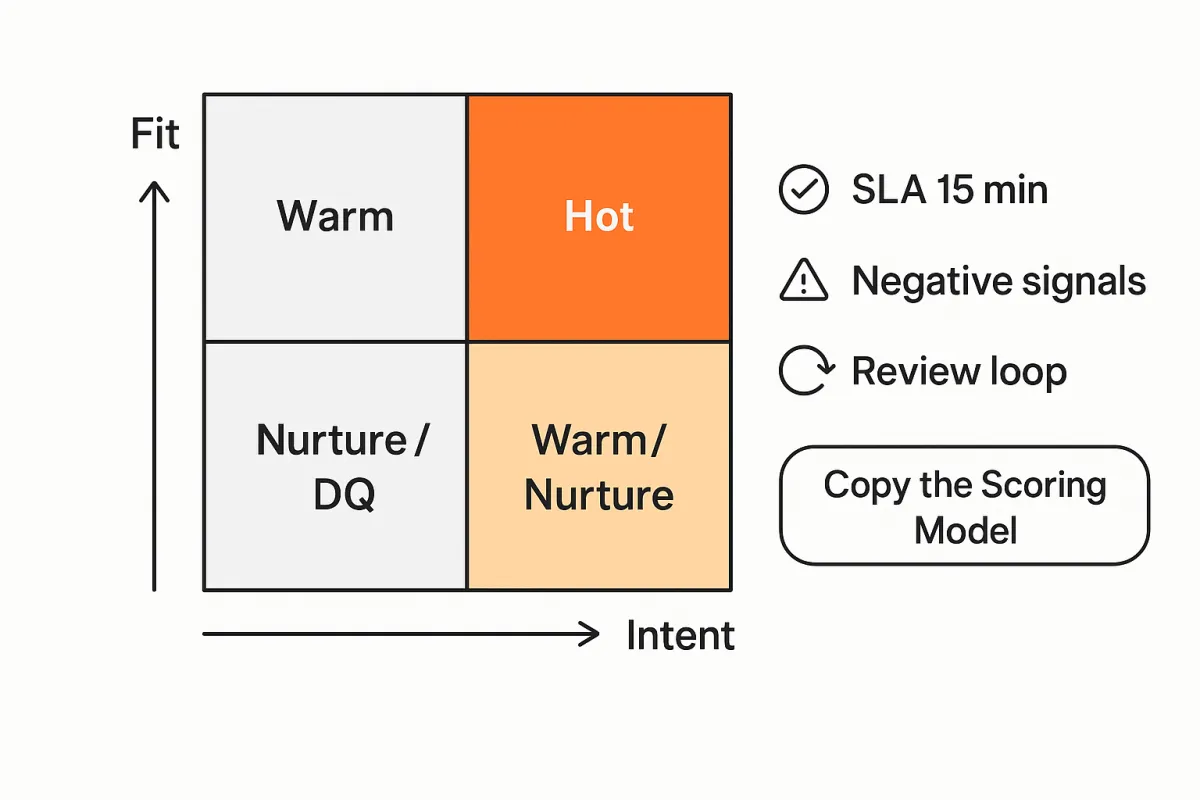
Principle: Great teams score both fit and intent—independently—and then unify them into a routing decision. Fit tells you should we sell to them? Intent tells you should we sell to them now?
Fit signals (ICP likelihood to succeed)
Emphasize attributes that correlate with successful customers, low churn, and healthy unit economics.
Firmographics: industry, company size (employees/revenue), geo availability, funding stage, multi-location, regulatory environment.
Role/Seniority: buyer persona match (economic buyer vs. user), department, title seniority.
Technographics: presence of complementary tools, data sources, CRM/MA stack compatibility, channel mix.
Use-case alignment: pain points that your product excels at, inbound problem statements that map to your core value prop.
Commercial feasibility: budget tier, procurement model, contract length norms in the segment.
Example fit tiers & weights (out of 100):
ICP Tier A (core industry + right size): +35
Correct buyer persona (Director+ in target dept): +20
Compatible stack (e.g., Salesforce + HubSpot): +10
Region we serve with support hours: +5
Known use case match (from form/free-text): +10
Budget declared in viable band: +10
Fit subtotal max: 90 (Reserve some headroom to avoid perfect scores)
Intent signals (readiness to act)
Stack rank by recency and depth—the “how soon and how serious” story.
First-party behavior:
High-intent pageviews (pricing, integrations, security/compliance): +15 each session (cap 30)
Product demo request or “talk to sales”: +40
Calculator/tool completion, ROI downloads: +10–20
Return frequency in 7 days (>=3 visits): +10
Email/SMS engagement: 2+ replies or clicked sales sequences: +10–20
Event signals: attended product webinar, asked buying questions: +15
Third-party intent: keyword surges, category research lists: +5–15
Peer/social proof touches: viewed case studies in same vertical: +10
Decay matters: Subtract –1 to –3 points/day of inactivity after peak signal to keep the queue fresh.
Combining fit and intent
Treat them as two axes with thresholds:
Hot (route to sales now): Fit ≥ 60 and Intent ≥ 40
Warm (SDR nurture/qualify): Fit ≥ 60 and Intent 20–39 or Intent ≥ 40 and Fit 45–59
Nurture (automated programs): Fit 30–44 or Intent 10–19
Disqualify (see rules below): Fails hard DQ criteria regardless of score
SaaS vs. Services nuance
SaaS leans heavier on intent depth (product pages, trials, integration docs).
Services/Agencies weight fit and timeline more (budget authority, project scope, geography), plus conversational qualifiers (authority, urgency, success criteria).
H2 Negative signals & DQ rules
Disqualification is not punishment—it’s focus protection. Build rules that shield sales time while preserving future relationships and deliverability.
Negative signals (score dampeners)
Use these to lower scores but not necessarily DQ:
Mismatched titles (student, intern, or unrelated function): –15
Free/disposable mailbox (e.g., mailinator): –30
Low-intent content only (career page, blog archive binge): –10
No-budget timeframe stated (“12+ months”): –15
Repeated bounces/soft spam indicators: –10 to –20
Competitive stack lock-in with low switch likelihood: –10
Hard DQ (auto-remove from sales queue)
These contacts should not hit an SDR/AE without review:
Competitors or agencies fishing for intel
Outside served geographies or compliance-restricted regions
Non-business email with no company context (e.g., personal Gmail for enterprise deal)
Clear misfit: industry you do not serve, employee size far outside ICP, or use case you explicitly don’t support
Malicious/fraud markers: form spam, mismatched IP/geo, known bad domains
Procurement blockers you cannot meet (e.g., mandatory on-prem when you’re SaaS-only)
Action: Apply “DQ—Hard” status, exclude from sales sequences, suppress from paid retargeting, and add a reason code.
Soft DQ (protect sales, keep the relationship)
These are not now but not never:
Too small/early today but in a growing segment
Junior researcher without authority but within ICP company
Budget freeze or “revisit next quarter”
Vendor already selected, but with renewal in 6–9 months
Implementation dependency not in place yet (e.g., data source migration underway)
Action: Move to “DQ—Nurture,” enroll in relevant education journeys (case studies, playbooks, ROI stories), and set a date-based re-evaluation task.
DQ reason taxonomy (make it reportable)
Keep reason codes short, exclusive, and exhaustive:
Competitor
Out-of-Geo
No ICP Industry
Too Small (Headcount)
No Authority
Budget/Timing
Tech Incompatibility
Fraud/Spam
Vendor Selected
Compliance Restriction
This taxonomy powers funnel purity metrics (e.g., DQ rate by source) and smarter media guardrails.
H2 Handoff to sales (SLAs & alerts)
Great scoring means nothing if handoffs are slow or noisy. Define who, when, and how—then enforce it.
Routing logic
Hot CQLs:
Owner: AE (or SDR → AE in <15 minutes).
SLA: First touch within 15 minutes during business hours; within 2 hours after hours.
Alerting: Instant Slack/Teams ping to owner + email to backup queue; create high-priority task in CRM.
Context payload: Fit score + intent score, last 5 activities, pages viewed, CTA clicked, persona, tech stack, DQ checks passed, suggested opener (e.g., “Noticed you compared our HIPAA controls and watched the EMR integration demo…”).
Warm CQLs:
Owner: SDR with a 24-hour SLA for personalized outreach.
Cadence: 10-day, 5-touch light consultative sequence.
Promotion rule: Escalate to Hot if new intent ≥ 20 in 3 days.
Nurture:
Owner: Marketing automation.
Programs: Persona- + stage-mapped drips, product education, light retargeting.
Queue hygiene
Auto-close stale CQLs after 14 inactive days unless scheduled activity exists.
Re-score overnight so reps work the freshest opportunities.
Feedback loop inside CRM: reps choose one of: Good Fit—Booked, Good Fit—Not Ready, Wrong Persona, Wrong Use Case, Bad Data, which feeds your model review.
Required CRM fields (make ops measurable)
Fit Score (0–100), Intent Score (0–100), CQL Tier (Hot/Warm/Nurture)
DQ Reason (if DQ), Lead Source, UTM set, Persona, Primary Use Case
First-Response Timestamp, Outcome Code (Booked/No Show/Lost Reason)
H2 Review loop (precision/recall of scoring)
Scoring is a model, not a monument. Treat it like a product: measure, learn, iterate.
Plain-English precision/recall
Precision answers: Of the leads we called “Hot,” how many actually became qualified opportunities?
High precision = reps aren’t wasting time.
Recall answers: Of all the leads that should have been “Hot,” how many did we actually label “Hot”?
High recall = we’re not missing gems.
You want balanced precision and recall—enough focus to keep reps efficient, but wide enough to capture true buyers.
Simple operational example
Last month you flagged 200 Hot CQLs. 120 progressed to sales-accepted opportunities (SAOs).
Precision = 120 / 200 = 60%.
Post-facto, you found 160 total leads that should have been Hot (based on outcomes), but you only flagged 120 of them as Hot.
Recall = 120 / 160 = 75%.
Interpretation: Your model is selective (good recall), but 40% of “Hot” aren’t passing muster. Tighten criteria (e.g., require pricing-page + demo request or persona seniority) or adjust decay to avoid stale intent inflating scores.
Review cadence & levers
Monthly model check:
Precision & recall by source, persona, industry.
Confusion patterns: What are you misclassifying? (e.g., Students marking “Director” on forms).
Drift watch: Have content mixes or channels changed? (e.g., new webinar series skewing intent).
A/B threshold tests:
Group A = current thresholds; Group B = +10 intent for Hot.
Compare SAO rate, Speed-to-first-meeting, and Rep time/SAO.
Feature tweaks:
Increase weights for high-signal events (e.g., security doc views for enterprise).
Add negative weights for weak geos or tiny deal sizes.
Introduce cool-off after “just researching/academic” reason codes.
Rep feedback incorporation:
Required “Outcome Code” + free-text reason—sample 20/week for pattern mining.
Use common “Not Ready—Budget” phrases to refine Soft DQ nurture tracks.
Reporting to keep everyone honest
CQL → SAO conversion by tier (Hot/Warm)
First-response SLA adherence and its impact on meetings booked
DQ rate by source (to adjust paid media guardrails)
Win rate & payback by Fit tier (proves the ICP definition)
Nurture recycle yield from Soft DQ cohorts (validates “not now” strategy)
CTA: Copy the Scoring Model
Want this model as a plug-and-play template (scores, fields, automations, alerts)? Copy the Scoring Model to your CRM/MA stack and customize the weights for your ICP, channels, and cycle length.
Quick-start checklist
Define Fit signals (firmographics, persona, tech) and cap at 90 points.
Define Intent signals (pricing/demo/ROI behaviors) with decay.
Set thresholds: Hot (≥60/≥40), Warm (borderline), Nurture (light).
Implement Negative and DQ rules with reason taxonomy.
Wire routing + SLAs (15-min on Hot) with Slack/Teams alerts.
Capture rep outcomes in CRM to power monthly precision/recall reviews.
Run A/B threshold tests quarterly; tune weights by segment (SaaS vs Services).
Build Soft DQ nurture programs with re-evaluation dates.
Notes on research inputs
Typical signals by market:
SaaS: integration pages, pricing calculators, trials, security docs, multi-user interest.
Services: scope clarity, project timeline, budget range, decision authority, locality, reference requests.
Precision/recall explanation: Use the definitions and example above with simple counts your ops team can replicate from CRM exports.
Sample DQ reasons that still allow nurture: Too Small, No Authority, Budget/Timing, Vendor Selected, Tech Incompatibility (with a roadmap).
Bottom line: Score fit to protect downstream success, score intent to protect time-to-revenue, and disqualify quickly to protect focus. Then—measure, iterate, and keep the model honest.
