Snapshots, Environments & Change Control
Treat automations like software releases to prevent breakage.
CTA: “Use the Release Checklist”
Modern CRM and marketing-automation (MA) stacks behave like software: they contain interdependent assets (forms, workflows, webhooks, triggers, tags, lists, scoring rules, SMS/email templates, landing pages, integrations) that run 24/7. A small “quick fix” in production can quietly break lead routing, double-message customers, or nuke attribution. The solution is to operate your automations with the same discipline used in engineering—clear environments, versioning, structured releases, and post-incident learning.
Below is a practical blueprint you can adopt in HubSpot, Salesforce + Marketing Cloud, Marketo, ActiveCampaign, GoHighLevel, or similar platforms—no new tools required.
Why prod edits are expensive
It’s tempting to “just change the filter” or “add one more action” in a live workflow. Those five minutes can cost five figures.
What goes wrong in production:
Invisible cascade effects. Adjusting one trigger can create loops (e.g., a tag adds a contact to a list that re-adds the tag), duplicate sends, or lost suppression logic.
Data drift. Renaming fields or toggling picklists invalidates reports, segments, and scoring rules. Dashboards “go green” while pipeline actually stalls.
Compliance exposure. A tweak to SMS keywords or consent flags can violate TCPA/A2P norms, especially around opt-in/out handling and quiet-hour policies.
Integration fallout. A field mapping change in your CRM can break downstream tools (billing, call tracking, analytics, support), producing silent failures.
Unmeasured impact. Fixes done live aren’t isolated, so it’s hard to attribute conversion bumps or dips to a specific change.
A quick back-of-the-napkin cost model:
4 hours of misrouted MQLs × 15 leads/hour × $120 CPL = $7,200 in wasted spend plus opportunity cost and reputational harm.
One compliance incident (unsuppressed SMS re-contacts) → carrier filtering and fines, then weeks of reduced deliverability.
Bottom line: Production is for serving, not building. Edits are expensive because they compound across assets you don’t see.
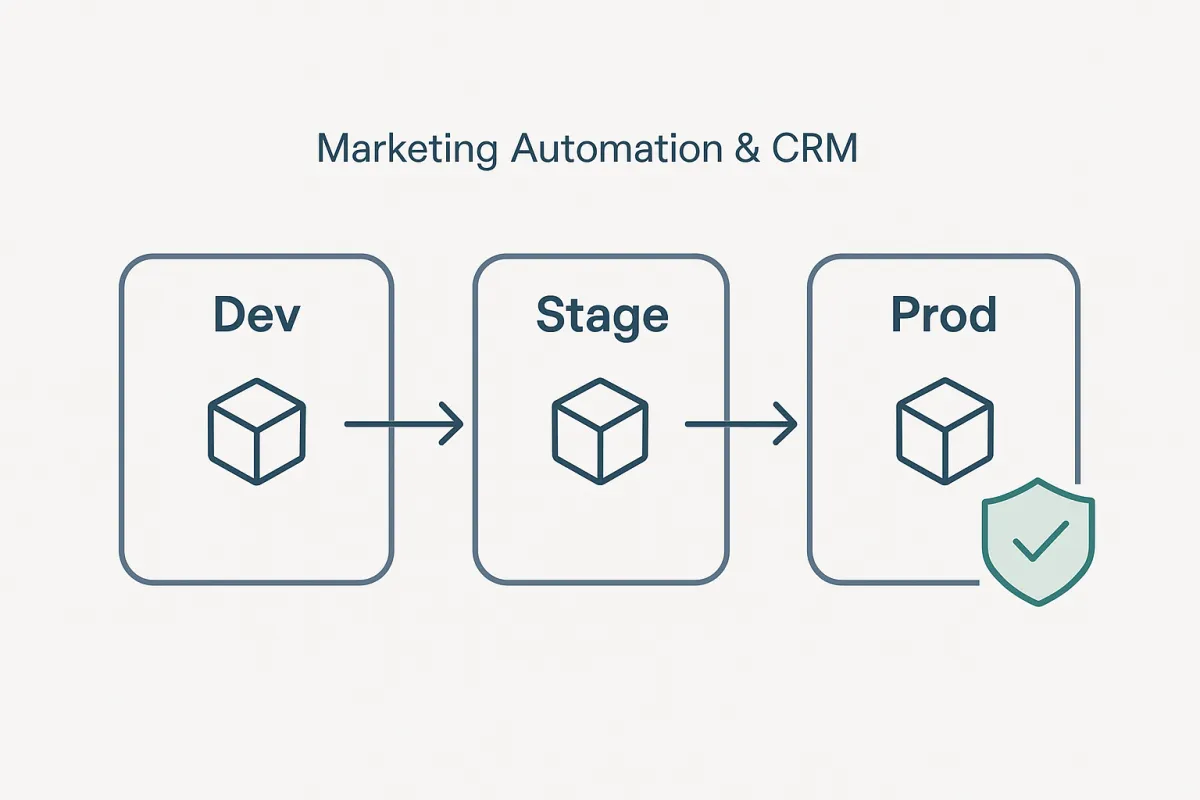
Dev → Stage → Prod snapshot flow
Treat your MA stack like a product with three environments:
Dev (Build safely): where you create and refactor assets with sample data.
Stage (Prove safely): where you test end-to-end with realistic data and real integrations turned down (limits, sandboxes, muted sends).
Prod (Serve confidently): where only approved, versioned snapshots are applied.
Key practices to make this work inside common CRM/MA tools:
Isolate assets by namespace.
Prefix everything by environment:
DEV — Lead Intake v3,STG — Lead Intake v3,PRD — Lead Intake v3.Use foldering and naming standards for forms, lists/segments, workflows, templates, webhooks, and pipelines.
Snapshot = portable bundle.
A “snapshot” is a frozen bundle of assets (flows, templates, fields, lists, tags, custom objects, scoring rules) you can export/import or clone. Most platforms support cloning; many offer JSON/YAML exports via API. Keep the bundle tight:Only include assets referenced by the release (reduce hidden dependencies).
Document external references (webhook endpoints, API keys, custom functions).
Seed data you can trust.
In Dev, use synthetic contacts/accounts with realistic formats.
In Stage, use masked copies of real records (hash emails/phones, scramble PII), or vendor sandbox data.
Pre-load edge cases: no-consent leads, partial addresses, duplicate phones, international numbers, invalid emails.
Guardrails in Stage.
Turn email/SMS to safe mode (address rewriting or internal seed list only).
Point webhooks to staging endpoints or a request bin.
Throttle job runners (e.g., 10/min) so you can observe behavior.
Promote with intent.
Promote Dev → Stage via clone/export.
Run end-to-end tests.
Promote Stage → Prod only when checklist criteria (below) pass and stakeholders sign off.
Tip: If your platform lacks first-class environments, emulate them with workspace folders, naming, and access controls (builders can’t touch PRD folders).
Versioning, diffs, rollbacks
If you can’t explain what changed, you can’t explain what happened.
Versioning conventions:
Use semantic versioning for bundles:
Lead-Intake 2.4.1Major = breaking logic or data model changes
Minor = new feature/treatment variant
Patch = bug fix or copy correction
Tag each release with a unique ID and date:
LI-2.4.1 (2025-09-17).
Diffs you can actually read:
Keep a CHANGELOG.md (or platform note) that lists:
Added/Removed/Changed assets
Field/Tag/Segment changes
External integration touchpoints (endpoints, secrets, scopes)
Migration notes (e.g., “legacy tag
Nurture-Engagedreplaced byNurture-Tier-2”)
When possible, export JSON/YAML of workflows and use a text diff tool to review logic changes. If your platform doesn’t export, capture screenshots of critical nodes before/after.
Rollbacks without drama:
Keep the previous stable snapshot ready:
LI-2.4.0.Make rollbacks idempotent: rolling back should replace entire bundles (flows + lists + templates) so you don’t strand dependencies.
Time-box the decision: if a release is causing material harm for >30 minutes and mitigation isn’t clear, roll back first, investigate second.
Feature-flag equivalents for MA stacks:
Routing flags: gate new logic behind a boolean field (e.g.,
Use_New_Router = true).Audience allow-lists: run new flows only for a seed list or internal test segment.
Rate limits: apply throttles or daily caps until metrics stabilize.
Soft launch by source: enable only for a specific source/UTM campaign initially.
These patterns let you “merge” to production while controlling blast radius.
Release checklist & stakeholder sign-off
A disciplined, repeatable checklist is your best insurance policy. Use this as a starting point and adapt per platform.
Pre-flight (Dev → Stage):
Naming & Foldering
[ ]All assets prefixed by environment and release ID[ ]Orphan check: no assets reference out-of-bundle items
Logic Integrity
[ ]No loops (entry/exit conditions validated)[ ]Suppression and quiet hours enforced[ ]Duplicate-prevention rules in place (email, phone, external ID)
Data Model
[ ]New fields documented (name, type, options, default)[ ]Consent flags and timestamps mapped (opt-in/out, source, proof)[ ]UTM/campaign attribution handled consistently
Messaging
[ ]Templates proofread and linted (links, variables, fallbacks)[ ]Unsubscribe/STOP/HELP compliant for SMS; one-click unsubscribe for email[ ]From names/domains and sender IDs verified
Integrations
[ ]Webhooks and API keys point to staging endpoints[ ]Error handling defined (retries, DLQs, alerts)[ ]CRM/op tools receive expected fields
Monitoring
[ ]Test events visible in logs; alerts routed to the right channel[ ]Early-warning KPIs defined (see below)
Promotion (Stage → Prod):
Stakeholder Sign-off
Marketing Ops reviewed logic and data model
Sales/RevOps validated routing and visibility
Compliance reviewed consent and messaging
Engineering/BI confirmed event/field integrity
Use a RACI to make this explicit:
StepMarketing OpsSales/RevOpsComplianceEng/BIExecAuthor change plan & snapshotRCCCIValidate in StageARRRIApprove promotion to ProdACRCIMonitor post-release & roll back if neededARCRI
Post-release (Prod, first 24–72 hours):
[ ]Watch error rates, spam/blocked signals, carrier filtering for SMS[ ]Validate lead-to-MQL speed, router latency, duplicate rate[ ]Compare send volume and conversion against control period[ ]Keep rollback plan warm until stability checkpoints are hit
CTA: Want a ready-to-use version? Use the Release Checklist to copy/paste into your PM tool or platform notes.
Incident logs and post-mortems
Incidents will happen. What prevents repeat incidents is how you capture and learn from them.
What to log for every incident:
Timestamps: first detection, stakeholder notification, mitigation start, mitigation end, resolution, rollback (if used).
Blast radius: segments affected, channels (email/SMS/calls), integrations hit (billing, analytics, support).
Customer impact: duplicate sends, missed SLAs, compliance exposure, revenue at risk.
Technical details: workflow IDs, fields/tags, API endpoints, error codes, rate limits, carrier responses.
Screenshots/artifacts: before/after logic, diffs, event logs, payloads (with PII masked).
Metrics that drive accountability:
MTTD (Mean Time to Detect) — tighten with better alerts and synthetic tests.
MTTR (Mean Time to Restore) — shorten with clear rollback steps and on-call ownership.
Change Failure Rate — percent of releases that cause an incident; aim to trend this down.
Escaped Defect Rate — issues not caught in Stage; invest in better Stage data and tests.
Blameless post-mortems (PMs) that actually work:
Facts first, interpretations second. Create a time-ordered event log before proposing causes.
Systems thinking over heroics. If success required a hero, the system is brittle.
Actionable remediations. Every root cause maps to a durable fix:
Add a pre-flight test (e.g., duplicate-loop detector).
Add a monitor (e.g., SMS STOP/HELP volume anomaly alert).
Adjust access controls (builders can’t edit PRD).
Improve rollout strategy (gate with allow-list, raise caps gradually).
Close the loop. Assign owners and due dates; verify in the next retro that fixes exist and are used.
A lightweight PM template:
Summary: What broke, who was impacted, business effect.
Timeline: Key moments from detection to resolution.
Root causes: Primary and contributing factors.
What went well / what didn’t: Learnings to keep or change.
Action items: Owner, due date, verification method.
Attachments: Diffs, screenshots, logs.
Research
CI/CD-style governance for CRM/MA: Borrow principles—separate environments, code reviews (peer reviews of flows), automated checks (linting templates), progressive delivery (allow-lists and throttles).
Rollback patterns & feature flags: Use environment-scoped assets, audience flags, routing toggles, and staged rollouts to reduce blast radius. Maintain previous snapshots for fast reverts.
Final thought
Marketing systems are production systems. By adopting snapshots, environment separation, explicit versioning, and disciplined change control, you’ll reduce outages, avoid compliance risk, and ship improvements faster. Treat every automation like a product release, and your revenue engine will run smoother—without the surprise fires.
CTA: Ready to operationalize this? Use the Release Checklist to standardize your next rollout.
